A client asked me to review an AI agent they had been building for three months before they took it to production. The demo was genuinely impressive. It could handle complex customer queries, retrieve order history, and escalate issues without any human prompting. The team had put real work into it.
Then I started asking the questions that every architect should ask before anything goes near production. What happens when a thousand customers hit the agent simultaneously? What prevents one customer’s session from contaminating another’s? If the agent decides to call an API it was never supposed to touch, what stops it? How do you prove to your compliance team that the agent behaved within policy last Tuesday at 11pm?
The room went quiet. Not because the team was incompetent. Because these are exactly the hard questions that no prototype ever has to answer.
This is the gap that Amazon Bedrock AgentCore was built to close.
AgentCore and Bedrock Agents: Not the Same Thing
If you read my previous article on Agentic AI with AWS, you will recall that I covered Amazon Bedrock Agents as one of the key orchestration services. I want to draw an important distinction here, because the two are frequently confused even by experienced practitioners.
Bedrock Agents is a managed, configuration-based orchestration service. You define a model, a set of action groups, and a knowledge base, and AWS handles the agent loop for you. It works well for teams that want to move fast without writing orchestration code. But it only works with models hosted in Amazon Bedrock, and it makes the orchestration decisions for you.
AgentCore is the production infrastructure layer underneath. It is framework-agnostic: it will host and scale agents built with LangGraph, CrewAI, LlamaIndex, or AWS’s own Strands SDK, regardless of which foundation model they use. AWS positions AgentCore as the foundational platform that powers all agent workloads, with Bedrock Agents drawing on the same underlying infrastructure capabilities. The managed experience you get from Bedrock Agents works precisely because that infrastructure layer handles the hard production problems underneath.
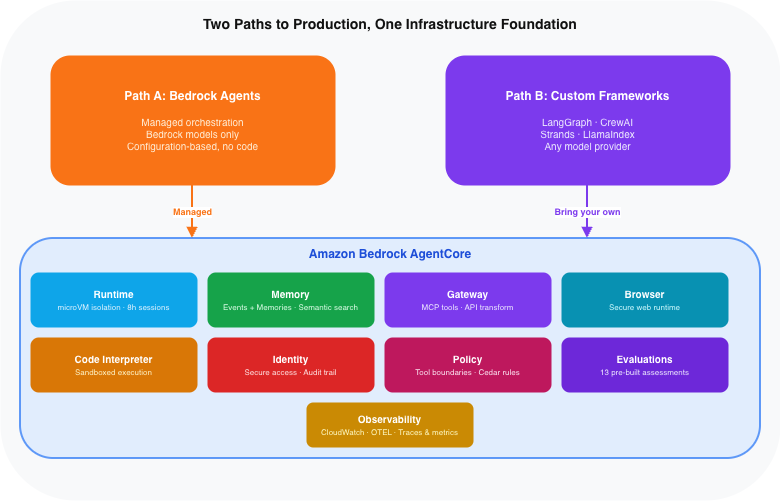
Think of it this way. Bedrock Agents is a furnished apartment: comfortable, ready to move into, everything already in its place. AgentCore is the building itself — the structural foundations, the electrical systems, the plumbing and fire safety infrastructure. You can live comfortably in the furnished apartment without ever knowing how the building works. But if you need to build your own space from scratch, or if you want to truly understand what is holding things up, you work directly with the building.
AgentCore became generally available in October 2025 and is now available in nine AWS regions — Asia Pacific (Singapore, Sydney, Tokyo, Mumbai), Europe (Frankfurt, Dublin), and US East and West. Singapore teams can deploy locally without sending data offshore.
The Nine Services of AgentCore
Amazon Bedrock AgentCore consists of nine services and capabilities. Rather than listing them, I want to explain each one through the real production problem it solves. That framing is far more useful than a feature catalogue, and it is what I wish I had when I first encountered the documentation.
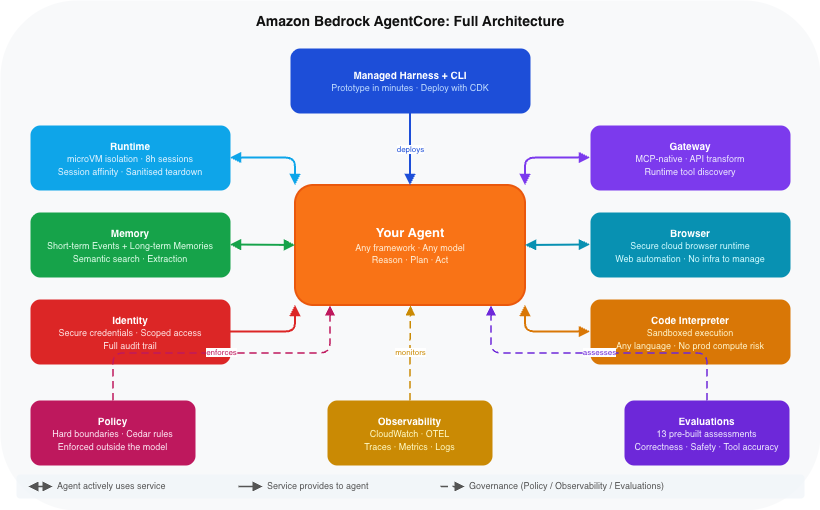
Runtime is the compute engine, and the direct answer to my “what happens at a thousand concurrent users” question. Each user session runs in a dedicated microVM with isolated CPU, memory, and filesystem resources. After each session ends, the microVM is terminated and memory is sanitised — there is no cross-session contamination, full stop. Sessions can run for up to 8 hours, which makes AgentCore suitable for long-running autonomous workflows that most serverless environments simply cannot support. The system uses a session header to maintain affinity, routing each request back to the correct microVM instance throughout the session lifecycle.
When I think about the Lambda spaghetti I built for SociallyClick a decade ago, where a problem in one function could disrupt everything downstream, Runtime represents everything I would have wanted then and did not have.
Memory is what separates a useful agent from one that greets you like a stranger on every visit. AgentCore Memory uses a two-layer architecture. Short-term memory captures raw events organised by session: conversation history, system events, state changes, anything that happened during the current interaction. Long-term memory extracts persistent insights across sessions using a two-step process — an extraction step that identifies what is worth keeping, and a consolidation step that determines whether to update an existing record or create a new one. Semantic search across long-term memory records means your agent can retrieve context relevant to the current query even when the user has not mentioned it explicitly.
Gateway solves the tool connectivity problem that every team building agents eventually hits. Your agent needs to reach your existing REST APIs, your databases, your Lambda functions. Rather than rebuilding your entire tool ecosystem specifically for agents, Gateway transforms what you already have into agent-ready tools with unified access across protocols, including native support for the Model Context Protocol (MCP). Tools are discoverable at runtime, so your agent is not statically wired to a fixed list of capabilities.
Browser and Code Interpreter are where AgentCore starts to feel genuinely different from anything that came before. I will be honest: when I first saw these two services together, I had to sit with it for a few minutes. Browser gives the agent a secure, cloud-based browser runtime to interact with websites and web-based services, without your team spinning up any browser infrastructure of its own. Code Interpreter lets the agent write and execute code in a fully sandboxed environment — calculations, data parsing, chart generation, scripting — without that execution ever touching your production compute. Together, they give your agent the ability to do real knowledge work, not just answer questions.
Identity handles secure cross-service access. When an agent acts on behalf of a real user — calling an AWS service, accessing a third-party API, making changes to a datastore — it needs proper credentials, proper scopes, and a full audit trail. In any regulated industry, this is a legal requirement, not a design preference.
Policy and Evaluations form the governance layer, introduced in preview at re:Invent 2025 and both now generally available as of March 2026. Policy sets hard boundaries on what an agent is allowed to do with each tool — rules you can write in plain language or in Cedar, AWS’s open-source policy language. Not what the agent can do by capability, but what it is permitted to do by rule, enforced outside the model so the model cannot reason around it. Evaluations provides thirteen pre-built assessment systems covering correctness, safety, and tool selection accuracy, among other factors. Together, they are the difference between walking into a compliance meeting with assurances and walking in with evidence. Any CTO who has shipped a production system that later caused a compliance incident knows which one they would rather have.
Observability rounds out the nine. It provides real-time visibility into agent operational performance through CloudWatch dashboards with telemetry data in OpenTelemetry-compatible format — session counts, latency, token usage, error rates, and execution traces across all AgentCore services. When something goes wrong at 2am, Observability is what tells you where to look.
What Arrived in April 2026
Three new capabilities launched in April 2026 that address a different problem altogether: how quickly a team can get from an idea to a working agent prototype.
The Managed Harness, currently in preview, lets you define an agent by providing a model, a system prompt, and a set of tools, then run it immediately with no orchestration code required. The harness manages the full agent loop — reasoning, tool selection, action execution, and response streaming. For validating whether an agent concept is worth pursuing before investing in full implementation, this changes the economics of experimentation significantly. It is available today in four regions, including Asia Pacific (Sydney).
The AgentCore CLI handles the other end of the journey. When your prototype is validated and ready for production, the CLI deploys it with the governance and auditability of infrastructure-as-code through AWS CDK, with Terraform support coming. The intent is that the same rigour you apply in code reviews and change management for traditional software now applies equally to your agent deployments.
Filesystem Persistence, also in preview, allows agents to suspend mid-task and resume exactly where they left off. For multi-hour autonomous workflows where an intermediate failure previously meant starting over completely, this is a meaningful reliability improvement.
Three Things Every Architect Must Internalise
I have seen enough AWS migrations and production incidents to know that the teams who succeed are the ones who understand not just what a service does, but the decisions it changes. So here are the three things I would want every architect building on AgentCore to internalise before going live.
First, the framework decision is entirely yours. AgentCore does not impose an orchestration framework. It will host LangGraph, CrewAI, Strands, LlamaIndex, or whatever you bring. That freedom is valuable. But it also means the quality of your agent’s reasoning logic is your responsibility, not AWS’s. AgentCore gives you the infrastructure. The orchestration quality is on you. Choose your framework deliberately, understand it deeply, and test it thoroughly before you need to debug it at 2am with real users affected.
Second, Bedrock Agents and AgentCore are not competing choices — they are a continuum. If you want a fully managed experience with minimal configuration and you are comfortable with Bedrock-hosted models, use Bedrock Agents. If you need framework flexibility, external model providers, or more direct control over the infrastructure layer, engage AgentCore directly. Many production systems will use both, with different use cases sitting at different points on that continuum.
Third, production readiness has a minimum viable checklist. Runtime for session isolation. Memory for continuity. Policy for boundaries. Evaluations for confidence. Identity for audit. Go live without any of these in place and you are not shipping a production agent. You are shipping a demo with real-world consequences. Period.
Closing Thoughts
In my previous article, I wrote that Agentic AI introduces something that none of the prior cloud evolutions did: agency itself. The system reasons, decides, and acts. AgentCore is AWS’s answer to what that actually requires at the infrastructure level.
The nine services of AgentCore are not features bolted onto a foundation model. Each one exists because there is a specific, real way that autonomous agents go wrong in production. Runtime prevents session contamination. Memory prevents amnesia. Gateway provides controlled tool access. Policy prevents unauthorised actions. Evaluations provide evidence. Identity provides accountability. Observability tells you what actually happened.
The question I keep asking myself these days is not “can we build an agent that does this?” Almost anything is possible now. The harder question is whether we are building the infrastructure to make it safe to run. Those are very different questions, and AgentCore is the clearest signal yet that AWS is taking the second one as seriously as the first.
So here is my question for you: of the nine AgentCore services, which one do you think most teams are most likely to skip, and why? I would love to hear your thoughts in the comments.
Date Published: 10 Apr 2026